[논문 리뷰] BEiT : BERT Pre-Training of Image Transformers

📄PDF Download - BEiT: BERT Pre-Training of Image Transformers
BEiT: BERT Pre-Training of Image Transformers (15 Jun, 2021)
Keyword
a self-supervised learning
MIM (Masked Image Modeling)
image patch
visual token & image tokenizer
blockwise masking
Summary
- 현재(2023.01.04) SOTA 8위 모델입니다.
- 자기지도학습(a self-supervised learning) 모델입니다.
- 자연어 처리에서 유명한 BERT의 원리를 적용하여, Vision Transoformer를 제안합니다.
- 기존의 이미지 모델이 BERT 방식의 masked image modeling을 적용할 수 없었던 이유와 해결방안을 제시합니다.
- Image Tokenizer은 DALL-E를 이용하였고, 미분 불가능 문제를 해결하기 위해 Gumbel-softmax relaxation이 사용되었습니다.
Abstract
자기지도학습 비전 표현 모델 BEiT입니다.
BEiT의 약어는 Bidirectional Encoder representation from Image Transformers인데, 아마도 BERT에서 파생된 약어 같습니다.* BERT (Bidirectional Encoder representation from Transformers)
자연어 처리 분야에서 유명한 BERT 모델에 이어, Vision Transformer를 만들기 위한 MIM(Masked Image Modeling)을 제안하였습니다.
각 이미지는 Pre-training 과정에서 Image patch와 Visual Token으로 표현됩니다.
BEiT의 과정을 요약해보자면, 먼저 원본 이미지를 Visual Token으로 "Tokenize"을 하게 됩니다.
그 다음 일부 Image Patch를 임의로 Mask하고, Backbone Transformer에 전달합니다.
Pre-training의 목표는 손상된 Image Patch를 기반으로 원래의 Visual Token을 복구하는 것 입니다.
Introduction
a self-supervised learning을 추진한 이유?
Transformer는 Computer Vision 분야에서 유망한 성능을 보였습니다.
하지만, 연구 결과로 보면 Vision Transformer는 CNN보다 더 많은 훈련 데이터가 필요했습니다.BERT의 원리
masked language modeling은 Text 내부의 Token 일부를 무작위 마스킹 한 다음,
그 텍스트의 Transformer 인코딩 결과를 기반으로 Mased Token을 복구합니다.BERT의 Image Version, BEiT
Vision Transformer를 Pre-training하기 위해 the denosiong auto-encoding 아이디어를 제안하였습니다.Vision Transformer의 문제점
이미지 데이터에 그대로 BERT를 적용할 수는 없습니다.
우선, NLP의 경우 사전에 정의된 단어나 어휘가 잘 정리 되어있지만 Image Patch의 경우 없습니다.
따라서 모든 가능한 후보를 예측하기 위해서 단순한 Softmax classifier를 사용할 수 없는 것 입니다.
Token을 쓰지 않고 Pixel 단위로 가능하지만 short-range dependencies와 high-frequency details만 학습이 가능합니다.
따라서 Pre-training된 Vision Transformer를 위해서 이러한 이슈를 해결하는 것이 목적입니다.
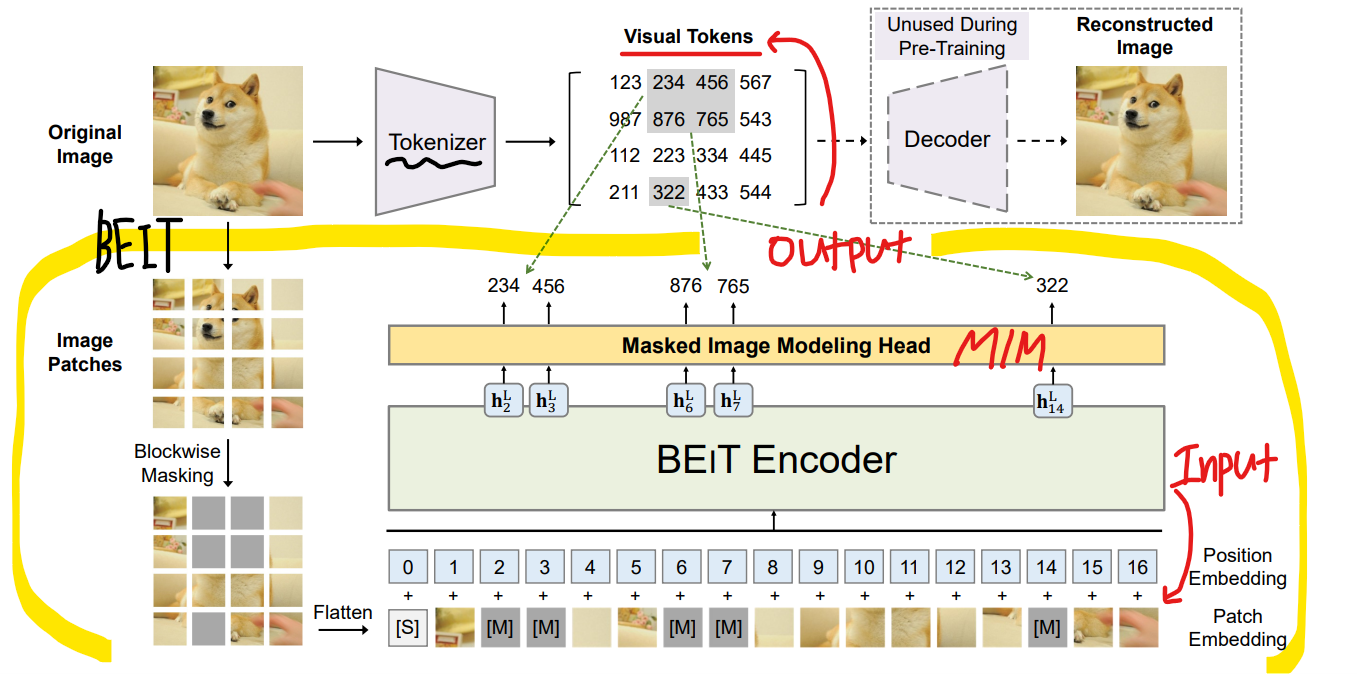
Original Image를 넣고 Image Tokenizer를 통해 Visual Token을 생성합니다.
그리고 Original Image는 Image patch로 나누고, Blockwise masking을 통해 블록 단위로
랜덤하게 Masked Image patch를 만듭니다. 그 다음 패치는 ViT(Vision Transformer)에 들어가게 됩니다.
MIM(Masked Image Modeling)을 통해 예측 Visual Token을 뽑아냅니다.
목표는 손상된 이미지의 원본 이미지 Visual Token을 예측하는 것이고, 이러한 복구 과정을 학습하는 것 입니다.
BEiT 모델은 새로운 모델을 소개한다는 것 보단, 기존에 있는 것을 이렇게 활용하면 성능이 좋아진다라는 논문 같습니다.Methods
Input Image x가 주어지면 BEiT는 Vector로 Encoding을 하고,
BEiT는 자기지도 학습 방식으로 MIM (Masked Image Modeling) 작업을 통해 Pre-training됩니다.
MIM은 Incoding Vector 기반으로 Masked Image Patch를 복구하는 것을 목표로 합니다.
Downstream(ex. Image Classification and Semantic segmentation) 작업의 경우에
Pre-train된 BEiT에 Layer를 추가하고, Parameter를 조정하여 사용할 수 있습니다.
Image Representations
이미지는 Image Patch와 Visual Token, 2가지로 표현됩니다.
Image Represnetations - Image Patch
224 x 224 크기의 이미지를 14 x 14 개의 grid of Image Patches로 나눕니다.
각각의 패치는 16 x 16의 크기를 가지고 있습니다.
Image Represnetations - Visual Token
Image는 raw pixel 말고 "image tokenizer"에서 얻은 discrete token을 사용합니다.
image tokenizer는 DALL-E Tokenizer(discrete variational autoencoder, dVAE)를 사용하여 학습합니다.2가지의 모듈 - Tokenizer, Decoder
Tokenizer는 Visual codebook에 따라 image pixel x를 개별 토큰 z로 매핑합니다.
Decoder는 Visual Token z를 기반으로 Input Iamge x를 재구성하는 방법을 학습합니다.Visual Transformer의 문제점
Visual Token은 불연속적이기 때문에, 미분이 불가능합니다.
Sampling의 문제인 미분 불가능 문제를 softmax로 해결하는 Gumbel-softmax relaxation을 이용하여 해결했습니다.
각 이미지를 14 x 14 그리드로 토큰화를 진행합니다.
*하나의 이미지에 대한 Visual Token의 수와 Image Patch의 수는 동일합니다.
*
Backbone Network: Image Transformer
ViT와 같은 백본 네트워크를 사용합니다.
Pre-Training BEiT: Masked Image Modeling
a masked image modeling (MIM)
Image Patch N개로 이미지를 나눈 후, 대략 40% 정도의 Image Patch를 Mask합니다.
Masking된 Image Patch를 learning embedding으로 교체합니다.
corrupted image patch는 L-layer Transformer의 Input으로 넣습니다.masked image patch = corrupted image patch
마지막 히든 계층에서 softmax classifier를 통해서 손상된 visual token을 예측합니다.
Pre-training의 목표는 corrupted image가 주어졌을 때 올바른 visual token의 likehood(y절편)을 최대화하는 것입니다.
우리가 또 주목해야 할 부분은 Blockwise Masking입니다.
마스킹된 위치에 대해 무작위로 패치를 선택한다고 했습니다.
그대신에 Blockwise Masking을 사용합니다.
Block 단위로 마스킹 되기 위해, 최소 패치 수를 16으로 정합니다.
그런 다음 마스킹 블록의 종횡비를 무작위로 선택합니다.
그리고 위의 문단에서 언급했듯이 마스킹 비율은 40%이기 때문에 0.4N을 얻을 때까지 위의 단계를 반복합니다.N은 총 이미지 패치의 수, 0.4는 마스킹 비율
MIM(Masked Image Modeling) 작업도 BERT의 MLM(Masked Language Modeling)에서 영감을 받았습니다.
또한 Blockwise Masking은 BERT에서도 많이 적용됩니다.
그러나 Vision Pre-Training을 위해 pixel-level auto-encoding을 직접 사용하면, short-range dependencies와 high-frequency details에만 집중이 됩니다.
BEiT는 discrete visual token을 예측하고, 고수준의 추상화를 요약할 수 있기 때문에
pixel-level auto-encodeing보다 훨씬 뛰어난 성능을 보여줍니다.
From the Perspective of Variation Autoencoder (VAE)
DALL-E의 Tokenizer는 discrete variation autoencoder 방식으로 학습되었습니다.
Pre-Training Setup
- (default) input patch size = 16
- 224 x 224 image size
- 14 x 14 grid of image patches
- 500k step (800 epoch), 2000 batch size, adam optimizer, learning rate 1.5e-3, warmup of 10 epoch
==> 1.2M 개, Nvidia Telsa V100 32GB GPU cards, 5일 소요 - pre-trained 모델 맨 마지막에 linear classifier 적용함
Fine-Tuning BEiT on Downstream Vision Tasks
- Image classification
- a simple linear classifier
- catecory -> softmax
- maximize the likehood of labeled data by updating the parameters of BEiT and the softmax classifier
- Semantic segmentation
- SETR-PUP를 모방함
- BEiT를 Backbone encoder로 두고, deconv layer를 이용함
Experiments
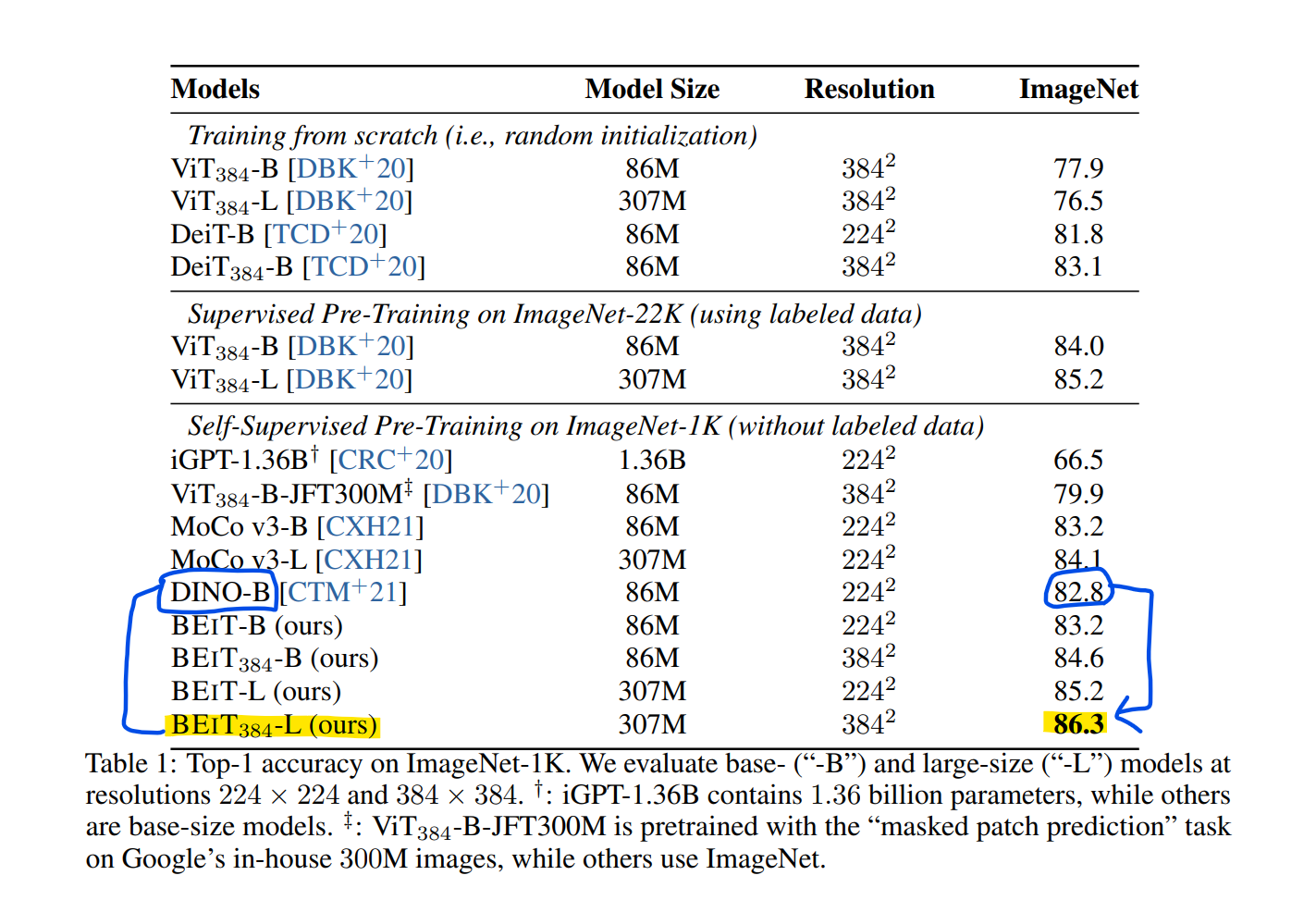
같은 self-supervised 모델인 DINO보다 더 좋은 성능을 보이고 있습니다.
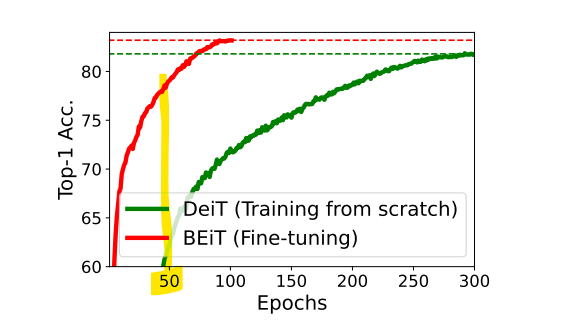
Ablation Studies
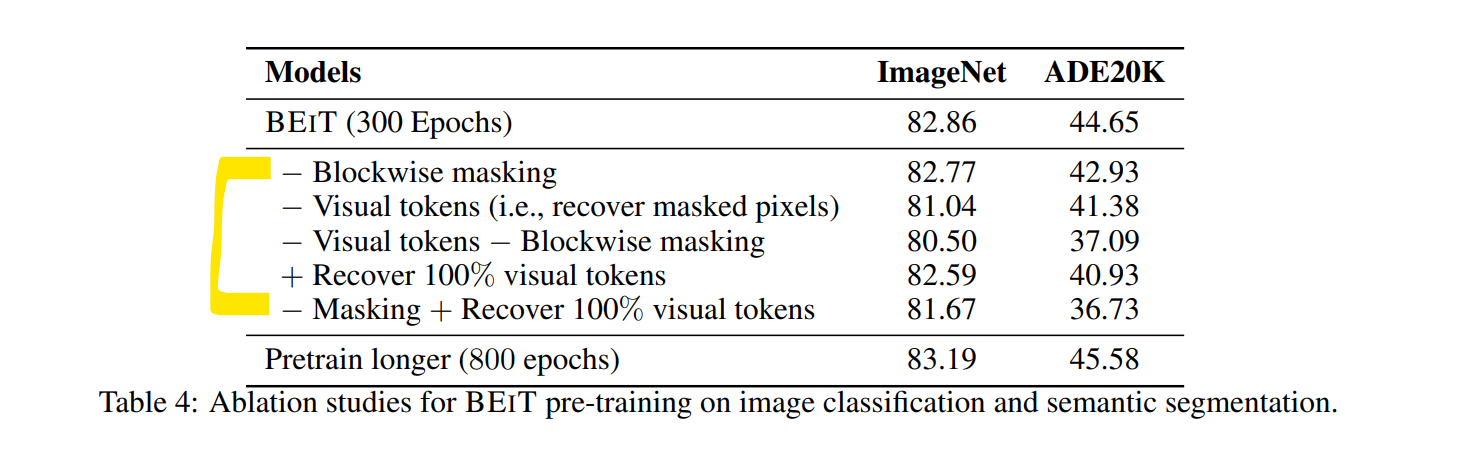
BEiT의 각 구성요소에 대한 기여도를 분석하기 위해 adlation studies를 진행합니다.
모델은 Image classification과 Semantic segmentation에서 평가되었습니다.Image classification = ImageNET, Semantic segmentation = ADE20K
Epoch은 300으로 설정하였습니다. (800 epoch 대비 37.5%)
1. blockwise masking
먼저 마스킹 된 position을 무작위로 sampling하여 blockwise masking을 제거합니다.
82.86에서 82.77으로 감소, 44.65 에서 42.93으로 감소하는 양상을 보아
특히 semantic segmentation에서 더욱 유익하다는 점을 알 수 있습니다.
2. visual Tokens
마스킹 된 패치의 raw pixel을 예측하여 visual token을 제거합니다.
즉, pre-trained 작업이 masked patch를 복구하기 위한 pixel 회귀 문제가 됩니다.
BEiT에서 쓰인 MIM 작업은 단순히 pixel-level auto-encoding 작업을 훨씬 능가합니다.
visual token을 예측하는 작업이 BEiT의 핵심 요소입니다.
3. blockwise masking + Vision Tokens
blockwise masking이 pixel-level auto-encoding에 훨씬 더 유용해서
short-distance dependency를 덜어준다는 점을 알 수 있습니다.
4. Masking + Recover 100% visual Token
모든 visual token을 복구하면 downstream의 성능이 저하됩니다.
5. 300 epoch vs 800 epoch
충분한 학습이 필요하다는 점을 알 수 있습니다.